Or, apples vs. papaya salad.
Short version: I’ve moved Tropology to PostgreSQL for performance reasons, and because after some evaluation, Neo4j wasn’t as good a fit as it seemed at first blush.
You may want to start by catching up with the other Tropology articles.
All done?
Neo4j’s pros and cons
The conceptual fit
Neo4j seemed like a very good fit at first. We’re handling connected data, in the form of which concepts are referenced from which articles. This could in theory let us do queries such as finding the various paths that lead from Lampshade Hanging to If it bleeds, it leads.
However, the model is too widely connected, with some major hub pages having thousands of outgoing and incoming links. Even after some judicious pruning, we ended up with 11,566,441 relationships and 222,384 pages.
This means that while Neo4j can help us find the shortest path between two concepts (which may be a direct link), finding a set of paths likely leads to a combinatorial explosion for even a set of paths that are just 3 nodes long.
This means such queries aren’t really useful for us… removing one of the great advantages of Neo4j.
Peculiarities
Neo4j isn’t without its share of idiosyncrasies.
Nodes have labels. The way I was originally modeling the data, a label was a conceptual group - for example, Film or Manga. Labels are not the same as a table, since a node can have multiple labels.
Neo4j nodes have properties, which don’t need to be present in all nodes. You can have indexes on properties, which is of course very useful for speeding up queries when, say, you need to find a specific node by its code. However, said index will not be used unless you also include the node’s label - if for any reason you don’t know a node’s label, you’ll trigger a full scan.
While this may seem like a small issue, we don’t really know which potential labels we have so we can declare the indices in advance - we get our categories from crawling the site. We could parametrize these, building queries on the fly and keeping track of which labels we have already created an index for, but we end up with a convoluted codebase that’s also much slower to import data into.
The faster way is actually keeping all nodes into a single, known label - Articles in this case - and using MERGE to create them all at once…
At which point we’re effectively doing the same thing as if we were keeping every node as a tuple inside a table in a traditional RDBMS.
Cypher
Neo4j’s Cypher language is very powerful, and it allows you to tersely express queries for node relationships. It’s not extensively documented, unfortunately, and while there is the Cypher reference card available there doesn’t seem to be a syntax specification that fully details how you can combine these into valid expressions (see the documentation for Postgres’ SELECT as a counter-example).
This may seem like a minor thing, but it ends up resulting in a fair amount of fumbling around, often until you manage to get advice from someone more experienced with the language. In my case, I was unaware of how could you do multiple UNWIND expressions, and was trying several syntax combinations until I got the right one from Michael Hunger.
And while I’m hesitant to put it this way… it would seem like Cypher needs better automated tests against regressions.
I was working on improving a somewhat naive query, which was taking about six seconds to return the relationships among nodes related to a large, well-connected article.
While I managed to get a succinct way in which to express this particular query, I wasn’t initially able to get the results I wanted. After testing across several versions, I realized it likely wasn’t a problem in my query: Cypher just isn’t behaving consistently from 2.1.2 to 2.2.1 to the version that powers Neo4j’s online console.
This lead me to search for other Cypher issue reports, and I found more than I was comfortable with. In the case of querying inconsistencies sometimes whomever files the issue adds an alternate, equivalent query that does work as expected, which could help you if you’ve tripped over that same problem, but the fact that I ran into a querying issue with a not particularly complex statement gave me pause.
On to Postgres
The migration
I could have continued using the slow version of the query above while either I found a workaround or Neo4j released a fix, but decided instead to take the time to run some tests on PostgreSQL 9.4. After all, if we’re already storing all nodes under a single label, that’s effectively the same as dumping them all into a table, so might as well try our hand at a regular data storage then.
Clojure shone again. Refactoring the db namespace internals went smoothly, and it’s amazing the difference that being able to do structured editing on your expressions makes. Not to mention, its focus on data handling and transformations works wonders. “Oh, you get slightly different result keywords from your new database? Just apply a map transformation!“
I’d dabbled in Korma before, so I chose it for the queries. It’s still a great way to write SQL in Clojure, but caveat emptor: if you’re dealing with query composition or more elaborate joins, the documentation could still use some more examples.
The results
Unsurprisingly, Postgres is significantly lighter. Look at that CPU usage drop for effectively the same process:
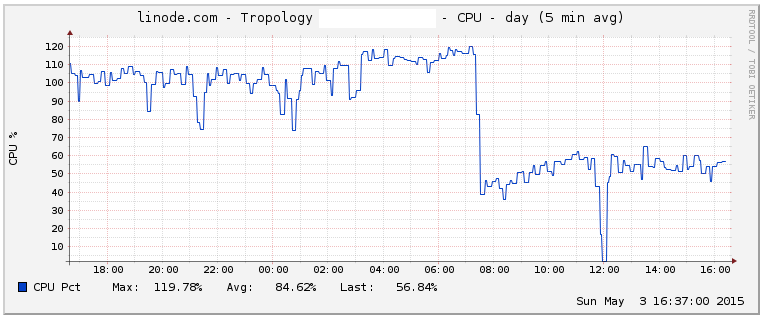
Funny enough, the amount of bandwidth being used is much higher. Guess why?
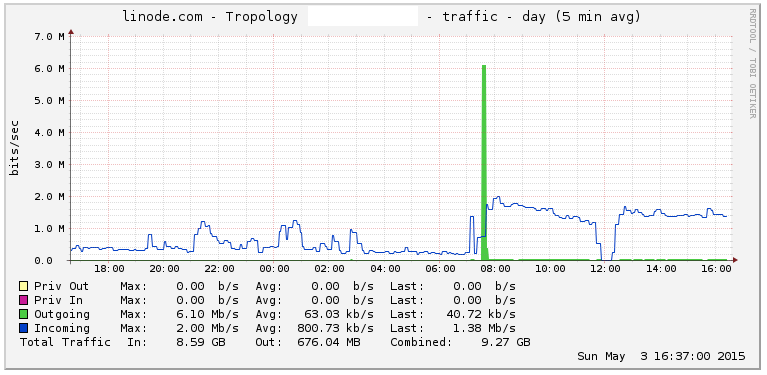
We’re getting at least a 4x increase on the number of pages imported, at 1/2 the CPU cost. That’s an improvement of at least 8x for those keeping score at home. And that’s considering that we’re storing a significantly higher volume of data now, since this branch caches the page contents on Postgres.
For the record, this example is in no way skewed towards Postgres. That data is running on a vanilla, untuned Docker container, and some of the queries are still naive because on my first pass my priority was retaining the same internal API while just migrating the data store.
Also, that multi-second query that made me trip onto the inconsistent result behavior in Cypher? It returns in < 300ms here.
Conclusion
Neo4j is a great tool, but is not necessarily the best one even for data that can easily be represented as a graph. You’d probably get significantly better results than I did when the connections between your nodes aren’t as dense as the ones on my model, when you know your node labels/categories in advance, and when you get to assign costs or other properties to the relationships to help with filtering.
Its power comes at a high CPU cost, of course, and it seems like on the testing and documentation departments it’s still not up to the standards of more traditional database systems.
When dealing with a large amount of densely-connected data that you need to get consistent performance out of, the old workhorses still have the edge.