Welcome. You may want to first catch up on Part 1 of this little experiment.
All done? OK then.
The whittling
So we have 220k nodes and 16MM relationships. Querying through them is less than speedy, even after we’ve ensured we’re using Neo4j’s indexes.
First step, clean up! Turns out we’re getting all links that match the markers we’ve figured out, but there’s some we could be ignoring because they’ll contribute nothing to our relationship analysis. Let’s look at the top pages in the database:
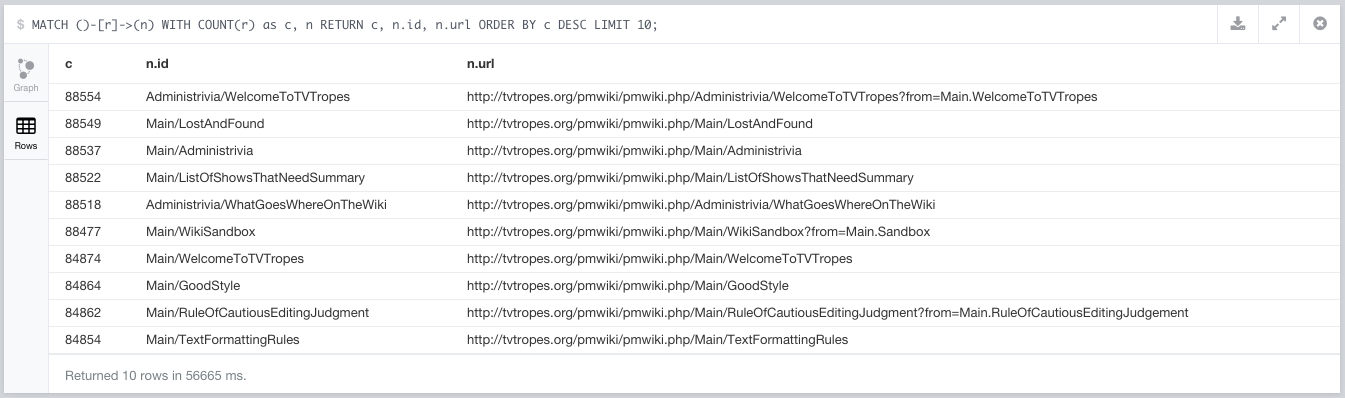
The following usual suspects keep turning up:
- Administrivia/*
- Main/LostAndFound
- Main/Administrivia
- Main/ListOfShowsThatNeedSummary
- Main/WikiSandbox
- Main/WecomeToTVTropes
- Main/GoodStyle
- Main/RuleOfCautiousEditingJudgement
- Main/TextFormattingRules
- Main/PageTemplates
On top of that, these were pages I was already thinking of excluding from visualizations, since they are part of what I consider volume outliers - pages referenced either so much or so little that considering them brings no extra information (the other end being misspelt URLs).
Cleaning this out gets us over 1MM relationships removed from the database. Once we’ve cleaned those up, we get the main categories as the most referenced nodes, which is as it should be.
Then there’s the Tropers pages, which seem to be the users. Deleting them from the current database removes 13444 nodes, with 29999 relationships.
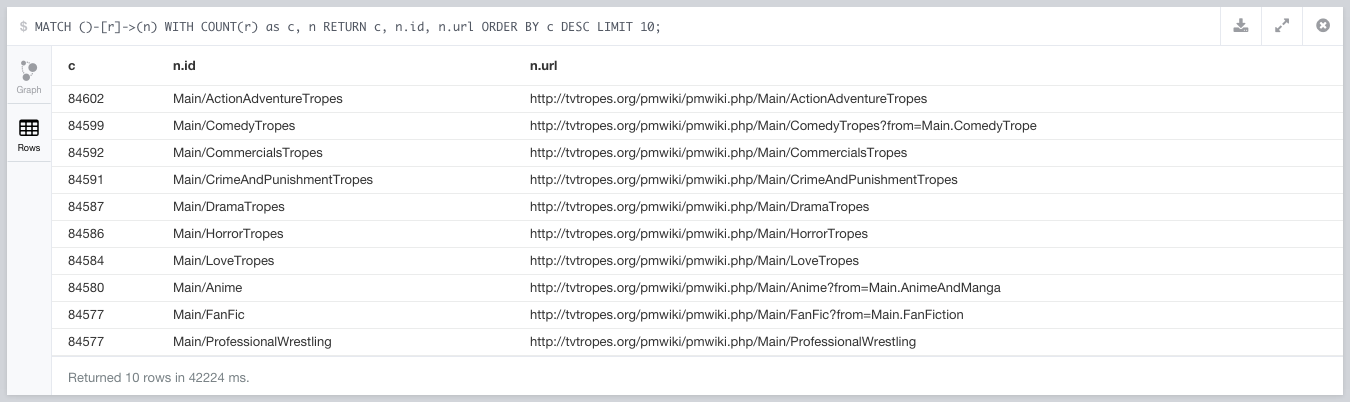
Once we get those taken care of, the top 10 linked pages are categories, which is as it should be (plus, you’ll notice the query took 20% less time to run). We may still want to exclude them from visualizations, but we’ll probably need them around for categorization and querying.
This clean up decreased the number of nodes to 206975 (down 13621), and that of relationships to 15110820 (down 1035056). That’s an improvement and will likely make queries less painful… but 15 million relationships is still a lot of any query to figure out possible paths through.
We also need to deal with our currently very slow import process, since the more data we can import, the easier it would be to figure out which of this data keeps popping up as noise.
The official route
Now, Neo4j does have their own batch inserter, but the database must be shut down before you try to write to it. This is not something we’d be importing live while people are querying the site.
So… our options seem to be:
- Retain the querying capabilities, but shut down the database periodically to mass import new data.
- Switch to a different database, where we can update data live in an efficient manner, but giving up some querying capabilities.
- Figure out how to best improve our current inserts.
Option #1 is a no-go - I want to have this live without having to keep bringing it down for maintenance updates. I’ve profiled option #2, and while I could be getting significantly better performance from PostgreSQL inserts (more on that later) I’m still reluctant to give up the querying capabilities that I get from Neo4j.
Let’s see what we can do to improve our inserts.
A refresher on our approach
As you remember, we:
- Start from a page.
- Create a node for it if it doesn’t exist on the database.
- Parse the page, and get all the references to other tropes.
- Import all the nodes that we don’t have already in the database.
- Create an outgoing relationship from the central node to all the nodes it references.
For each and every one of these nodes, we:
- Look for the node’s code to see if it exists,
- When that returns empty, create the node,
- Once I get the node, do another call to assign the label.
This means we could end up with 4 REST calls for every node in a page (exists?, create, label, link) on a scenario where pages can have hundreds of outgoing links. Some research indicates every call will also result in Neo4j writing to the transaction log and flushing it to disk, incurring an extra cost even when running on a SSD.
This will not do.
Batching things ourselves
Let’s suppose that we get a group of URLs to update the links for, and we’ll treat them as a batch. This means we’ll be creating the nodes that every page references but does not yet exist, and linking to them uniquely.
We have an issue here, which is that Neo4j’s cypher may not be as expressive to allow us to do everything we need to do in a single call.
For instance, can we assign labels to nodes just as we create them? We also need to assign different labels to different nodes - could we do that in a single call? We already saw that Neo4j doesn’t seem to use indexes unless we include a label - can we pass multiple labels as a parameter, or do we need to exclude them?
It doesn’t seem like we can pass multiple labels (or at least not with neocons). When querying for a list of IDs, this leaves us with something like
MATCH (n) WHERE n.id in {list} RETURN n
You’ll see there is no label usage, which will likely result on us missing the index, but let’s roll with it for now.
We can also mass-set the labels for each group of IDs…
"MATCH (n) WHERE n.id in {ids} SET n :" label " RETURN n"
Once we figure out which of those nodes we need to create, the ideal thing to do would be to group all create invocations to a single back end call. But again, we don’t seem to be able to parametrize labels, so we’ll need to compromise and make a call for each label group, and make two calls: one to create the nodes, and one to assign a label for them.
Finally we take this chunk of nodes coming from a single source (say, Anime/CowboyBebop) and create outgoing links pointing to them.
So far so good. Our operation is summed up as:
- Query for all ids we care about, in a single cypher call
- Filter out those that are missing
- Split the missing nodes into groups
- Mass-create the nodes for every group by first using neocons’ create-batch, then using a cypher query to set the label for all those nodes in the group
- Return the combined list of created and retrieved
Expressed in Clojure:
Which, if I may make an side to rave, is one of the reasons why I bloody love the language - you can see how clearly those 5 points are expressed on the handful of lines of code up there.
Doing some performance tests, calling batch operations seems to significantly improve performance, even if we do end up doing that sort of grouping.
A similar batched test of creating 1000 node and adding the same label to all of them completes in 2.3s. It’s an unfair comparison, since we get to add the label in a single call, but likely indicates we have some good performance improvements ahead of us (even if we need to make multiple calls, one per each group of nodes falling into a label).
So let’s run it with Anime/CowboyBebop, which used to take 52 seconds on our test Docker container.
The total run time now is…
drum roll
12 seconds.
Not bad. We’ve cut things down to 25%, and given the parallelization improvements we’d seen before (where a single page may take 52 seconds, but we could parallelize multiple calls to import about 25 pages per minute) we should be golden, right?
Pop goes the pmap
Wrong. This is not necessarily an improvement.
I can no longer parallelize importing, since more than one import may find the same node they reference missing, and both may try to create it. This will cause the process to barf because of unique constraints, since both parallel processes are unaware of each other attempting to create the common node.
Some numbers… Importing a single page on the test environment used to take 50 seconds. Now it takes 12 seconds. Woo! However, we can only run one at a time, meaning we would get about 10 in 2 minutes. Boo! Before we used to be able to run about 50 every two minutes, since we could thread all the things.
We’ve just forcibly serialized our entire flow.
So I’ve cut the import time of an individual page down to a fraction of the time, but given the extra sanity checks that stop me from parallelizing import this has the effect of significantly increasing total import time of a group.
Next steps
This is hinting at an issue on how we’re grouping the calls. Perhaps we shouldn’t be considering how to parallelize multiple node import calls, but instead how to best group them so if many of the pages we’re importing reference the same node, we also save up on the time to query for it existing and (if it doesn’t) then creating it.
We should also probably reconsider modeling. If we lump all concepts into a single label - say, having them all under Trope, using other labels for our own data, and storing the category as a property. This would have two major advantages:
- We would save the need to group the inserts, which would potentially cut the Cowboy Bebop insert from 12 seconds on 2.5.
- I’d be able to skip grouping by label above, or the indexing miss issues that come with not knowing what the label for something is.
It probably means re-writing everything to do these filtering and grouping, and dumping the current cypher code for the Neo4j’s REST batch API which works based off their internal IDs.
Then again… The reason for using Neo4j is that I’m trading raw insert speed for the possibility of doing some queries that wouldn’t be as easy in PostgreSQL, like the shortest path. Given that getting a set of paths seems to be out of reach given the current data volume, however, just dumping Neo4j and going to a minimum viable product over PostgreSQL which just looks at the immediate neighborhood would be an option.
We’ll look at these next.