Introduction
This is the first part of a series of articles on a small experiment I’m building. The intent is to crawl TVTropes, to find possible relationships between tropes and the material they appear in, as well as shared concepts.
I want to be able to not only visualize a concept and the tropes that it links to, but also how they relate to each other. A bonus would be being able to query how far away a concept is from another - for instance, how many steps we need to take before we can go from Cowboy Bebop to Macross Missile Massacre.
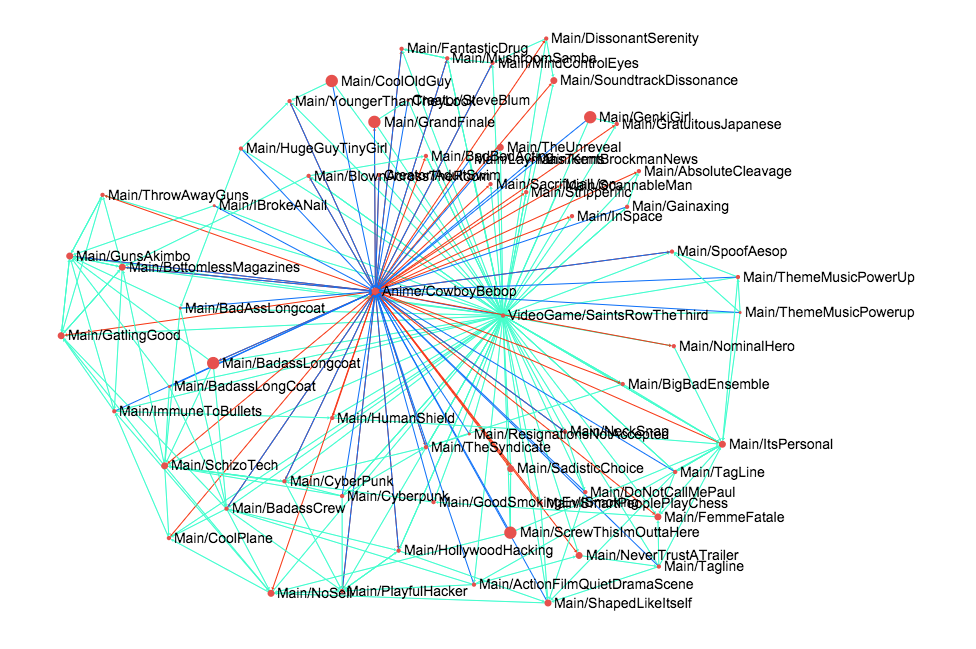
Take for instance the (admittedly quick-and-dirty draft) visualization of the tropes shared by Cowboy Bebop and Saints Row: The Third.
The platform
Clojure excels at data handling and transformation, so it was my first choice for the language. It also allowed me to get more experience with ClojureScript and Javascript interop, since I would need to create the visualizations on the front end.
On the data storage end, this sounded like a perfect job for a graph database, since effectively we’re recording directional relationships between atoms and we want to be able to map paths. After a quick search, Neo4j seemed to be the better established and documented one. The existence of Neocons, an idiomatic Clojure client for the Neo4j API, sealed the deal.
I had initially thought about doing the visualizations with D3.js, which is a general library for manipulating documents based on data. While reading Scott Murray’s great D3 tutorials I found a mention of sigma.js, which is graph-specific. It provided a much faster start up with less code than D3, so I decided to go with it.
The data import process
The initial naive data import process was:
- Start from a page.
- Obtain the page’s node identifier. This is based on the next two items after the URL, so in the case of identifier Anime/CowboyBebop, the Neo4j label would be Anime.
- Import the node if it doesn’t exist on the database.
- Parse the page, and get all the references to other tropes. These seem to be identified by starting with the URL http://tvtropes.org/pmwiki/pmwiki.php/, and having the class twikilink.
- Import all the nodes that we don’t have already in the database.
- Create an outgoing relationship from the central node to all the nodes it references.
Lather, rinse, repeat until you have crawled the entire site.
The Clojure story
Clojure did not disappoint. I’ll write more about it once I’ve open sourced the project, but for now, suffice it to say that it’s been a pleasure to work with, even when the code you’re writing amounts to you thinking out loud and will need constant refactoring or rewriting. Cursive Clojure has been a gigantic help as well.
Neo4j first impressions
This was my first encounter with Neo4j, so I’d love to hear from you if some of the impressions below are wrong. I’ve been around the Neo4j IRC channel, but while populated it seems exceedingly quiet.
I started off using individual calls for Neo4j’s REST API. I quickly found out some peculiarities.
First off, while I have a natural string identifier (the Anime/CowboyBebop described above) all Neo4j identifiers need to be integers. This meant that I could not just use them as the retrieval key, but had to store this natural identifier as a node property.
Sure, node properties can be indexed (more on this later) but that meant that I couldn’t just retrieve a node even when I had what I knew to be a unique identifier, but had to do a search of it.
Second, the node create API did not let me assign a label. I had to create the node, get the resulting Neo4j id, and only then I could assign labels to it.
This means that effectively, importing a single node required three API calls:
- Look for the node’s code to see if it exists,
- When that returns empty, create the node,
- Once I get the node, do another call to assign the label.
This turned out to be a less than efficient process. Each call has a certain overhead, since it means Neo4j ends up committing to the transaction log. While every call takes a relatively short time, I am making a lot of them. A single page like Cowboy Bebop can end up having over 700 links, each one potentially requiring 3 or more REST API calls.
On this profiling example (running inside a Docker container, after all the optimizations I list below) we can see that the total time to import a page is 51 seconds. A full third of that is going to assigning the labels, the second third to creating the relationships, and the rest to querying for the nodes and creating those we don’t find.

This is obviously obscene and, given the thousands of pages on the site, needs to be significantly improved.
Once we do get the data into the database, Neo4j’s web-based querying environment does allow for some interesting (if limited) prototype visualizations:
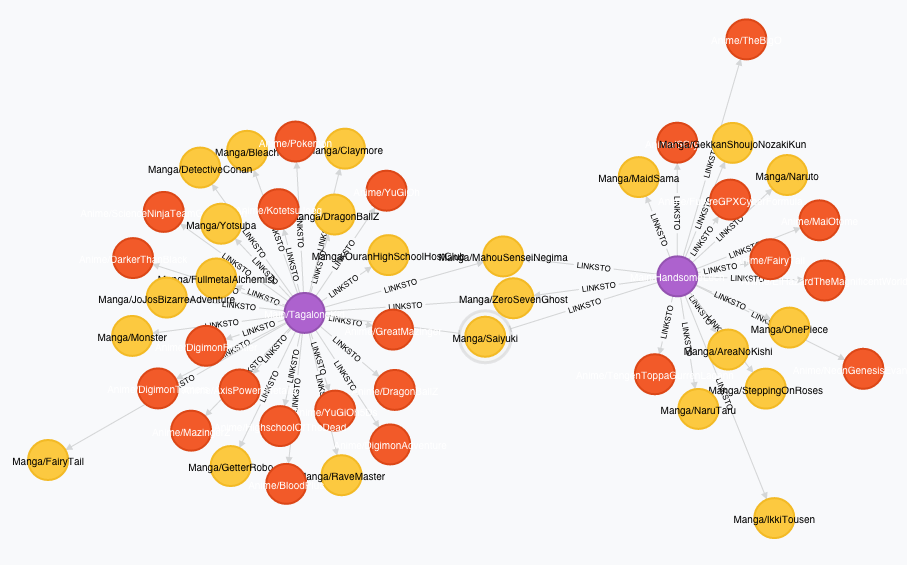
We can’t live with that query time, but fortunately there was some optimization low-hanging fruit to take care of.
- While importing a single big page can take 40+ seconds, every import process checked for its referenced pages before creating them. This means we could run multiple of these in parallel using Clojure’s pmap. I found that using a 4-core Linode, I could import between 20 and 30 pages in parallel every two minutes - meaning the averaged-out import time was about 4.8 seconds.
- Neo4j provides an auto-indexing capability, so I could index the internal code and a few other properties to speed up querying, however…
- The indexes seemed to have no effect at first. Some testing determined that Neo4j has a preference for queries that include labels (maybe it’s siloing the data and treating a label as a table), so even if a field was indexed, there was a significant difference between querying for the same field if you included a label than if you didn’t. How significant? Not including the label was 40 times more expensive and involved a full scan.
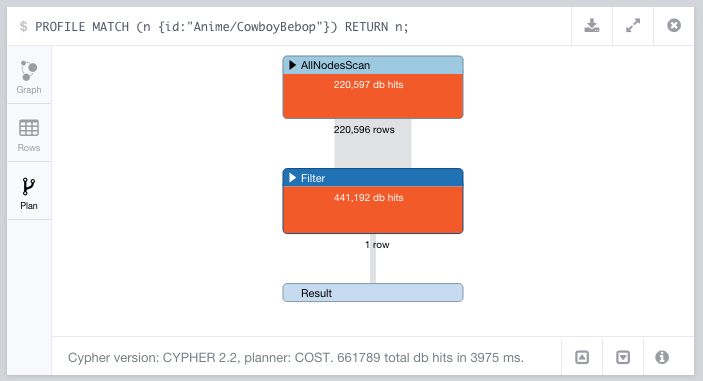
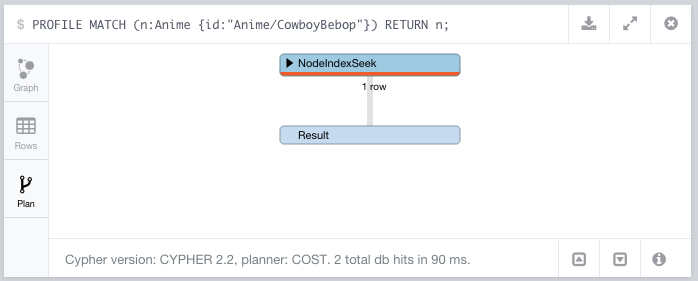
Having done these optimizations I managed to get the import process to add between 40 and 50 pages and their references every two minutes on the same Linode, meaning we had gotten the process to about 2.6 seconds on average per page if we can execute a them in parallel.
Clearly the transaction log hit on Neo4j’s end was still high.
The data volume
Something we haven’t gone into is exactly how much data we’re handling here. It’s not a six node toy graph. At this point, the database has:
- A total of 220596 nodes,
- Out of which 88536 have been imported and have outgoing links,
- For a total of 16145876 relationships.
How’s that for a platform stress test?
I do need better filtering to see which pages I end up importing and which ones I discard (and have found some improvements while writing this) but even 4000 articles with an average of 250 links each would yield 1 million relationships.
The issue is that the same machine that gets pegged with the crawling process is the one that is supposed to answer queries. With such a dense network of relationships, I hardly think we’re going to have an easy time finding a set of paths that are even 4- or 5-hops long… and indeed Neo4j tends to bail out when attempting it, no matter if that’s the only thing the server is doing. Shortest paths, however, do return blazingly fast.
I am therefore currently having to limit searches and visualizations to only a central node, its immediate neighborhood, and the relationships between the nodes in said neighborhood.
Coming up next
Low-hanging fruit was only going to get me so far, so I decided to look deeper into how to best batch operations. On my next article, I’ll go into the trade-offs of that process. I’ll also discuss some likely modeling improvements that may speed up the insert process.