Flexibility Through Immutability, part 2: How and When?
The second part of the original text for “Flexibility Through Immutability“.
The first part focused on the why of immutable data. On this part I’ll review what to do about if you’re working on an object-oriented language.
How to go about it, the OOP way
The available tools
Luckily, we already have tools in place that can help you do this, and I’m going to go over four simple principles.
My focus here will be mostly on how they apply to C# and Java, since .Net and Java is where I’ve done most of my recent work on, but I’m sure you can take the concepts and translate them elsewhere.
Structs help
Structs can act as a kinda immutable gateway drug. I’m wondering, however… who ends up using more classes than structs?
So am I suggesting you just struct everything?
Not quite. There’s advantages to having classes, like the fact that they’re nullable (value types aren’t). But using structs when you can will get you part of the way there, since we do get some enforcement already on what can happen with a struct.
Don’t mutate your objects
Just don’t mutate your objects. Return a new value instead.
Suppose you have a Vector type. It stores data for a 2D or 3D vector, and has methods to operate on it.
If you need to normalize the vector (making sure it has the same direction but a length of 1) don’t write a Normalize() method that changes it, have a Normalized property that returns a new vector instead.
If you need to take an Employee record, and increase its salary, don’t just to employee.Salary += 100; have a employee.SalaryChange(100) which returns a new Employee.
Does this sound familiar?
Remember the Builder design pattern? We want to start thinking along those lines.
You’ll also be able to chain operations, and end up with more fluent code.
Use iterators and LINQ
There’s no problem that can’t be solved by an extra layer of indirection.
I’d take the advice of “not writing for the implementation, but for the interface“ one further: write your code for Enumerables, not for Collections.
Also, if you’re using C#, or Java 8, you should be using the functional facilities to generate values.
- Use Where to filter
- Use Select to generate new collections (that aren’t, and might just be an iterator spitting out values from the existing one, but who cares? It’ll return something you can’t change)
- Etc.
Use immutable collections
Collections will be more involved.
Or would, if you had to implement them yourself.
Fortunately, there are already libraries for .Net and Java for immutable collections. These provide Add/Remove/etc methods which are not in place, and which return a new collection when you “modify it”.
By doing this, even if we have a case like the one for the Fisher-Yates randomizer from part 1, you know nobody will mutate any collections it holds form under it, and invalidate any pre-calculated information it may be storing.
That’s pretty much it
By doing these four things, and applying them with methodically, you’ll see the benefits we have discussed and remove a whole class of errors.
Or again, you can start using a nice, compact programming language that supports immutable data natively (along many other great features).
Where to do this?
Application logic
Using it on your business logic should be a no-brainer.
Whether you have a monolith or a bunch of micro-services, you have a big layer where your business logic lives.
Logic. Logic is about reasoning according to strict principles of validity.
It is about deriving what your next state should be, based on the last state and transformations that you are applying.
There’s nothing in that definition about keeping track of a whole bunch of independent but subtly inter-related states which may mutate from under you, and striving to minimize the collateral damage.
Make your business logic handle immutable data.
UI
Chances are anything that’s UI related, which is effectively about encapsulating state, is going to be a pain with the current tools unless it has a degree of mutability (although approaches like re-frame do a great job of reducing mutability to a single point). Those might not be as good a target, if the UI is simple.
Or that’s what I would have said some months ago.
re-frame
Is the GUI something that holds state?
I’d actually argue that the GUI is something that represents and that we use to manipulate state.
You’re going to say potato/potatoe here, but stay with me for a moment.
Now, we still have the word state in there. Where does this state come from?
If you have your entire application represented as immutable data, then that state is nothing but the last iteration of all the functions applied to the data that you use to build it. Said functions are triggered from the UI, but no UI component holds state itself.
This is the approach that re-frame, a ClojureScript library, uses. Even if you’re not working in Clojure, or planning to work in Clojure, I recommend you give it a read. I’ll have you thinking about UIs differently.
Defold
Now, you can be thinking “well, that’s all fine and dandy for web apps. If you’re showing a couple of divs and a list, anything will do“.
If you’re thinking that, I recommend this talk about how King.com used Clojure for their Defold game engine IDE to solve an entire host of problems that a mutable approach was causing.
Their implementation involves multiple components, each of which can have multiple inputs and have elaborate internal computations.
Their UI ends up represented as a graph of the data used to render it, which is then pulled by the UI rendering.
So apparently, it works the other way around.
Mutability is fine when you have two divs and a list, but after a certain level of complexity, immutability also makes your UI life easier.
Data layer
Then there’s your data storage. That sorta kinda needs to change over time, doesn’t it? Doesn’t seem like a good target either.
Not only there’s Datomic already, but even if you can’t switch databases right now, keeping immutability in mind when designing your system can help significantly.
For example, consider a system with a financial component. You have financial transactions, which may be deposits and withdrawals. Their status will change over time, from when they are created to when they’re finally processed.
Do you keep a single transaction record, with a Status column that you change every time the transaction is updated?
I hope not.
For systems that are heavy on financial transactions, and where accountability is paramount, my usual approach is that we never mutate a transaction status.
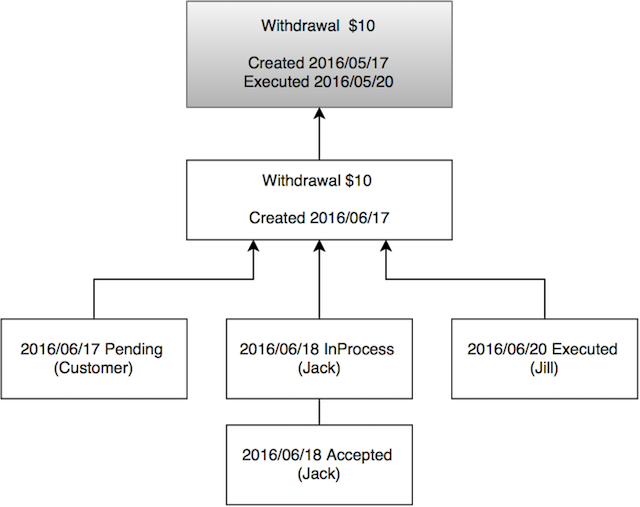
What we do instead is:
- Record the transaction status at every point in time;
- Have a materialized view that looks at the latest status;
- Define some statuses (Declined, Canceled, Executed) as final, after which a new status couldn’t be recorded.
If you have ever done something like this, then you’re effectively dealing with immutable data, because you can go back to your financial transaction as it was at any point in time, and see when its state changed. You can recover that world view.
Where not to do this?
That will actually be more of a question of environment, not of domain.
Is RAM a concern? Say, are you making Android apps? Well, this will have a hit.
Is raw performance a concern? For instance, are you doing a game, and altering a whole bunch of properties every frame? You will be paying a GC hit as well.
In any of these cases, you’ll need to do it judiciously. It’s up to you to evaluate what judicious means.
What’s in it for you?
Reasoning
Everything we do as developers is about trade-offs. By using immutable data, we are trading off a slightly higher memory usage, and a potential garbage collection hit, so that we get a cleaner code base that is much easier to reason about.
And I’m never going to get tired of saying this: code is read more than it is written. A codebase that is easier to reason about is an asset that will continue to pay off.
Refactoring
You’ll have an easier time refactoring code.
You’ll no longer have to wonder “what’s going on inside this method call? If I move it elsewhere, do I affect the result?”
All that will matter is “am I using this return value now?” If not, you can move any and all operations that deal with it to where you think they better fit.
Simplification
More importantly, you’ll be writing code that’s easy to delete.
The moment that you don’t need a result value, for whatever reason, you can just delete whatever is used to calculate it… because you know that code can’t possibly be having any other side effects that the application was relying on.
Offloading processing
If you need to offload processing of a data item to a separate thread, you won’t have to deal with locks.
If you need to offload processing of a data item to a separate machine, having had the discipline of keeping immutable data in the first place will make it much easier: you know no computation in the system depends on a value that’s being mutated elsewhere, so there’s no reason why that computation needs to even happen on the same box.
No memory involved
You won’t have to worry about who’s holding your objects, or where else in the application flow they might be being changed.
It doesn’t matter, because it can’t happen.
Nothing that you do with them will affect those other functions or objects… because nothing you do will actually touch values they might be holding.
Comprehension
Immutable lets you focus on comprehension, not memory. When reviewing code, you’ll be able to use your time to understand the operations involved, without having to keep mental track of invisible side effects.
I keep making this point, which is not particularly popular since it’s not an alpha-brogrammer kind of thing, but our brains suck.
They are limited. We forget things. We make assumptions. We get distracted. When we juggle a lot of things, we’re going to drop a few balls.
All things considered, it’s a wonder we manage to build the things we build.
The fewer assumptions your brain has to make, the fewer aspects of the codebase you need to memorize, the better off your entire team will be.
Conclusions
As counterintuitive as it might be, immutability lets you change your mind. It lets you change your mind about implementation details, about when processing is taking place, or even about where it’s taking place.
We are too used to having to trust we are in control of our codebases. But if something can mutate, somebody will mutate it, and at that point you lose control.
To be in control of the code, you have to know how it behaves. Mutability demands you take things on faith. Faith is at odds with knowing, and you need to know your codebase.
If you have been working in a purely object-oriented manner for a long time, it’s time to get some new patterns into your brain. Make them functional ones, so they can help you replace trust with certainty.
Published: 2016-06-15