Here’s the original text for “Flexibility Through Immutability“, for those of you who prefer reading to watching a video.
It’s a bit of a long read, so I’ve divided it into two parts. The first one focuses on the motivations behind preferring immutable data, and the second one (which will go up on Wednesday) on how to go about it.
The slides are at Speakerdeck.
Introduction
Warning
Talk contains opinions and anecdotal evidence.
If you are allergic to either, I recommend taking out the epinephrine.
There’s not way to avoid have it full of anecdotal evidence. It’d be real nice if I could stand here and present some iron-clad, generic, globally demonstrable arguments as to why you should do this, maybe based on a wide study across equivalent teams with a control group. Truth is, all we really have is our own experience. Your mileage may vary, to each their own and other clichés.
And since we have opinions, this is not a master class. On the plus side, since we are dealing with opinions, and we don’t have a certain amount of course material to get through, you are all free to interrupt me at any point and challenge them, and I’ll be happy to incorporate this into the discussion.
What we’ll talk about
- Immutable data, and why?
- Advantages and trade-offs
- Four simple things that help if you’re using an OO language that does not enforce it
Getting to know each other
About me
- I’m Ricardo J. Méndez, and I run Numergent.
- I work mostly with data-oriented projects on media, health-care information management, and financial companies.
- I run project-specific, distributed development teams.
- Doing software development professionally for 20+, and hacking around for longer.
About you
Who here is doing daily work on a language that does not provide memory management? Say, C++?
If so, this will not be as useful. For you to get value out of data immutability, without having to build a whole bunch of rigging somewhere, changes are you’re going to need some form of garbage collection.
Besides that…
- Who’s working on a functional programming language?
- What’s the rest of you working on? Python? Java? C#?
- Who’s already using immutable data somewhere?
My path here
Come for the functional approach, stay for the immutable data.
I started doing functional programming as a way to learn something new, because it was different from what I was working on.
It promised I could learn a new way of thinking. Learning something new, in particular something that forces you to think in a different way, gives you a new perspective on things.
Refactoring realization
Thing is, when I started doing functional programming more and more, I realized there was an unexpected benefit.
Code which was purely functional, and which did not mutate data, was easier to refactor.
C# Example one
And by that I don’t mean just adding parameters. Take a look at this code. Pretty straightforward function, right?
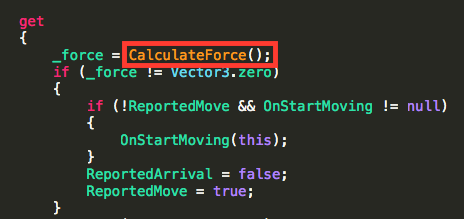
It made me realize that before even moving method calls around before, we had to make sure that we kept in mind whatever mutations whomever had written the method had implemented.
What if we don’t need a result value anymore? Well, we can’t just remove the call, can we? We need to make sure that there aren’t any other side effects being caused by the method, before we can do so.
Mutability surprise
What if “CalculateForce” is setting a flag for “last time calculated”, or a cache of the result, which something else relies on?
Now, on this case I know it’s a simple function, and the only thing that does is calculate a vector and return it, but you don’t.
You, who are looking at code from the outside, have to take that on faith.
And if you’ve never in your career run into a surprise of this type, left by an inexperienced developer, or even by an experienced developer who just hacked some functionality quickly… you’re a lucky, lucky engineer.
C# Example Two
Now, how about this case here?
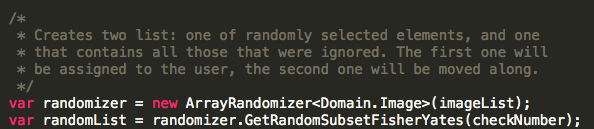
Fairly easy to read, right? We instantiate a randomizer, pass it a list of elements, and it returns a random subset.
Now, there’s two problems here. The first is that it returns a list. This means anyone who gets ahold of this list, can change it, and can change the elements in it.
The second one, is that the randomizer is initialized from a list, and keeps it so that it can be run multiple times. What if that list changes from under it? What if some of the elements contained on the list are destroyed?
Why immutable data?
Reasoning
This sort of case, which I could go on about for hours, gets us to the why of immutable data.
- There’s no friction-less movement. The fewer moving parts we have in our system, the less friction we’ll get.
- A nice side effect is that when you are dealing with immutable data, you stop thinking about operations, and start thinking about results.
- This is because if your data is immutable, you don’t have to wonder about what a method might be doing, deep in its guts - you just have to think about what it returns.
- Functions that act on the same data set become idempotent. This also means that, if you want, you can memoize it.
Yes, I’m pretty much saying “be more functional“. If you are already sold on that idea, and actively doing it… well, still stick around, you can help me convince those who aren’t.
Immutability vs. Stateless-ness
Immutable data tends to get conflated with stateless-ness, which I disagree with, and I think it’s the wrong way of looking at things.
You have a state. Your state is your world view. You have a preferred language, a preferred framework, you have likes and dislikes. Chances are, those likes and dislikes were different 10 years ago.
Now, unless you have the memory of a goldfish, you remember your old state. If you have a bucket in your head for things you like, you didn’t just completely throw out the memory of the items that were in it when you added new ones. You can reference that old state, and evaluate why you made some decisions the way you did in the past.
You changed state, but you didn’t discard your knowledge of the previous one. You didn’t just overwrite it.
We are aiming for that.
A functional approach
Functional programming
I’m not going to bore you with the Wikipedia definition of functional programming, make you read a bunch of text, but will point out what we’re aiming for here… which is:
- You have functions that get a bunch of inputs, and have a single output value (which may be a composite like a tuple or collection).
- Values are immutable. We don’t change them. They don’t change themselves. Nobody changes anything.
- Functions do not trigger any side effects on the inputs, the output, or anywhere else.
Functional is an approach. It’s about learning different semantics, a point I made on a Clojure talk I gave at the Bucharest Functional Programming group.
But it doesn’t necessarily mean you need to learn a new syntax, however simple and elegant Clojure is, to do it.
Make it boring
Last week at the Bucharest Functional Programming group Constantin Dumitrescu called pure functions “the most boring thing in the universe“.
Yes! That’s exactly what they should be! You should be excited about boring! Your basic building blocks should be boring and predictable, not thrilling and surprising.
It’s what you create with them that should be exciting.
The string argument
Take strings, for instance.
Anyone here using C# or Java and doesn’t understand how strings work?
Who here thinks strings are exciting?
Anyone worried that when they pass a string to a function, it’ll end up changed, for no apparent reason? Maybe have characters missing, or be all caps, or trimmed?
Are you concerned that if you use a string as the key to a dictionary, it may get changed from under you?
Any of you have to actually look up how strings are implemented to confirm this behavior?
That’s because strings are immutable. There’s no method you can call for a String object which operates on the string itself - anything that effects a change, will return a copy.
This means that strings are boring, reliable data objects that you can just trust.
What we do in OOP
And yes, you’re going to say “But clearly this shows I can already do this in C# or Java!”.
Sure, we can. But we don’t, really, do we?
We have a DoSomethingToObject() method that returns void but changes a bunch of values. We have Add/Remove/Clear methods which operate, in place, on the collection itself. We have ref and out parameters. And then we pass these objects around, so that other objects may end up holding them, and god forbid call Add/Remove themselves as well.
Readability vs. comprehensibility
Scary Clojure code
First, an aside. Suppose I show you some code
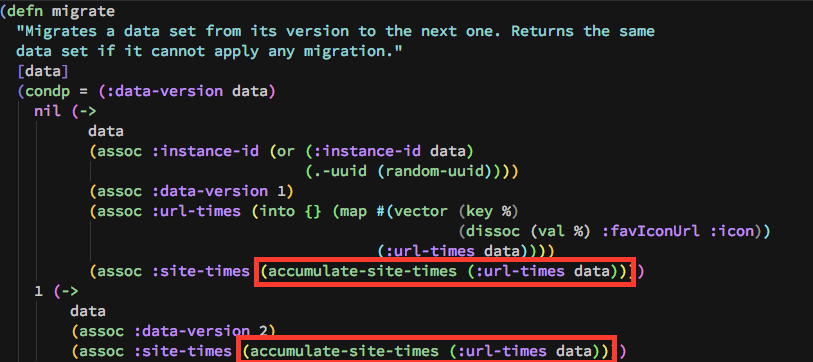
This is scary Clojure code. Who can read Clojure code? Who thinks this looks mostly like un-intelligible gibberish?
The unknown function
Now, after a bit of looking you notice that this takes a bunch of data, transforms it, and then accumulates it using a function.
There’s two things we could do here, if we want to find out what’s going on inside this function.
- We can poke it, look at how it behaves, see what it returns. Tests are one way of doing this.
- We could continue reading the code, all the way down, to figure out every little thing that happens. Bear in mind at this point we don’t know what how accumulate-site-times does its thing - for all we know, there’s even more calls under there, and any one of them could be touching the hash map it receives
I think we can all agree that option 2 is more time consuming. Do you even know how deep the rabbit hole goes?
How to approach unknowns
However, if you’re dealing with mutable data, option 2 is the only way to be truly sure of what’s going on. After all, there could be some mutation hidden in there that you are not aware of yet, that isn’t fully tested, or that you’re just missing in your initial evaluation.
Now, let’s assume that you do want to go with option 2. For that to be possible, you need to:
- Have access to each and every source involved on your system,
- Have the time available to go through them.
Because everyone knows that if there’s something that we usually have a lot of on projects, it’s available time, right?
There’s unknowns everywhere
The thing is that, the larger the team, the bigger the odds are that one of these two things will happen.
Not everyone will fully understand the subtleties of the language
- Are you using C#? Do they fully grok LINQ? Or are they cargo-culting part of it?
- Are they - god forbid - a bit fuzzy on ref vs. out?
Not everyone will fully understand the subtleties of your codebase
- Do they not realize something is a struct, and being passed as a value instead of reference?
- Did they see a property called obj.SomeValue, and not realize it’s actually getter/setter methods?
- Did they see a obj.GetValue() and not realize someone broke Single Responsibility inside?
When someone steps on either of these landmines, and you’re mutating data inside, you’ll find yourself in much bigger trouble than, if whatever mistake they make, they can’t trigger any side-effects.
Single responsibility principle
Suppose you apply the Single Responsibility Principle religiously.
First, as I’m sure we’ve all encountered (and I’d like to discuss further about your domain if you haven’t), cross-cutting concerns make drawing single-responsibility lines non-trivial, and involves a certain amount of you “making a call“.
But suppose we can. Suppose no method does more than one thing, so that it’s trivial to know at a glance what that method does.
The applications we build are not that simple. After all, if they were, pretty much any solution would do.
You’re going to end up with a bunch of methods. Eventually, they’ll become unwieldy, and you’ll wrap them in a single call. You’ll encapsulate them.
We like encapsulation. It helps reduce mental clutter. It also obscures. And when something is obscured, we - by definition - miss things.
Comprehensibility
What I’m saying is that when you worry that Clojure, or Scala, or F# code seems unreadable to you, you’re worrying about the wrong thing.
Readable is a matter of habit. God knows Romanian can seem unreadable to a foreigner, but the locals don’t seem to have a problem.
What we should be striving for is not just readability, but comprehensibility. Readability is only one factor for that.
Next up
On part 2, we’ll go over code comprehensibility, how to attack these problems in an object-oriented context, and the trade-offs involved.