DECEMBER 2015 UPDATE: I’ve run some tests with the latest ClojureScript and made some minor changes to the code, which significantly improved performance. Read this post for updated numbers. Keeping this post around for archival reasons.
The set up
This whole thing started not as a performance test, but as me experimenting with ClojureScript and Quil while reading Matt Pearson’s Generative Art. As such, it is not the most scientific of comparisons, and instead born out of my notes when exploring how to do sketches with ClojureScript for the web.
Consider the following example:
It initializes a number of circles with a random radius and movement direction, and then each frame we:
- Update their positions,
- Evaluate overlap if any of the circles overlaps with any other, and finally,
- When two overlap, draw a circle at the overlap center, with a radius of the overlap amount.
As you can see, it’s unlike a visualization where you take a set of existing items and display them, but it requires us to alter a significant amount of data every frame. I wrote it first on ClojureScript but my initial implementation had some serious performance issues, so after optimizing a bit I decided to rewrite it on CoffeeScript for a performance comparison.
Some notes:
- I’ve written Clojure before, even if I’m still a relatively new user.
- This was the first bit of CoffeeScript that I wrote, and I mostly picked it because I wanted to compare on the browser and I’m not too keen on Javascript.
This means that chances are both pieces lend themselves to optimization, but I don’t expect one language had an unfair advantage over the other (unlike, say, if I’d written one of the examples in C#, where I have a much better idea of the optimization trade-offs).
Performance
The initial ClojureScript implementation used maps for everything, which was horribly slow - I got about 9fps for 100 circles. A quick profile showed that a lot of time was being spent on accessing the map elements, and changing it so that the circle information was passed as a datatype improved performance by 300%.
As David Nolen commented on Twitter:
@argesric there's a reason ClojureScript always supplies lower level facilities - this is how the data structures are written
— David Nolen (@swannodette) January 7, 2015Here’s the frames-per-second that Chrome reported for each implementation:
| Circles | CoffeeScript | ClojureScript |
|---|---|---|
| 100 | 38 | 27 |
| 150 | 34 | 6 |
| 170 | 32 | N/A |
| 200 | 25 | N/A |
| 350 | 8 | N/A |
Unsurprisingly, CoffeeScript comes out ahead on something that requires a lot of data modification. What did surprise me was how much better it scaled: it took 350 wandering circles for the performance of the CoffeScript version to drop as far as the performance the ClojureScript implementation had with only 150.
It could be argued that the comparison is unfair, since CoffeeScript gets to be mutable and if performance is the main constraint, then the GC cost of immutability is likely to bite you when doing an example such as this one. Valid points, but I precisely wanted to push ClojureScript to see how it behaved in this case, and as I mentioned only thought about doing a CoffeeScript variant for comparison afterwards.
I then tried to find out where that time was going…
Profiling
… which brought me to the next issue - the ClojureScript version has significantly more noise in the profiler, making optimization more difficult. Check for instance this trace:
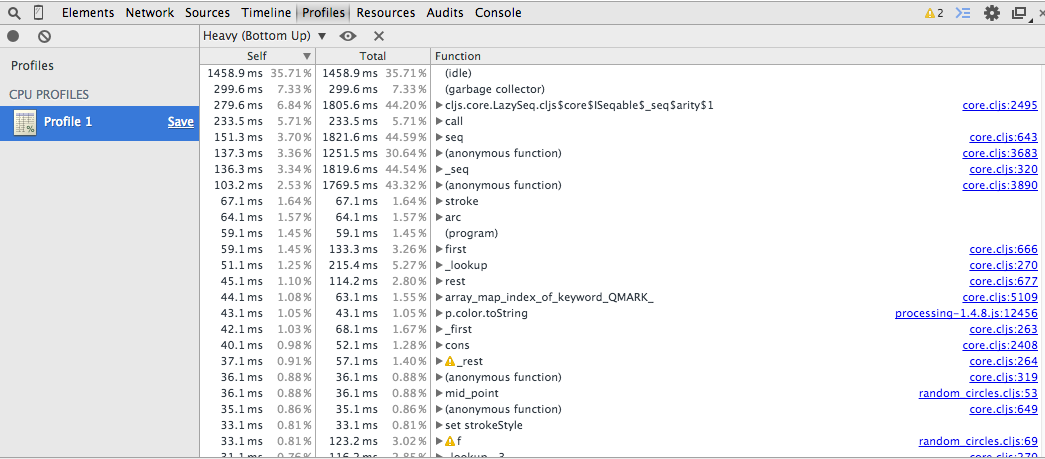
Most of the time is being spent on garbage collection or on core functions. Our own code is in random_circles.cljs, which as you can see is way down the list. There must be some of our own functions involved in there, of course, but we need to dig really deep to figure out which of them are.
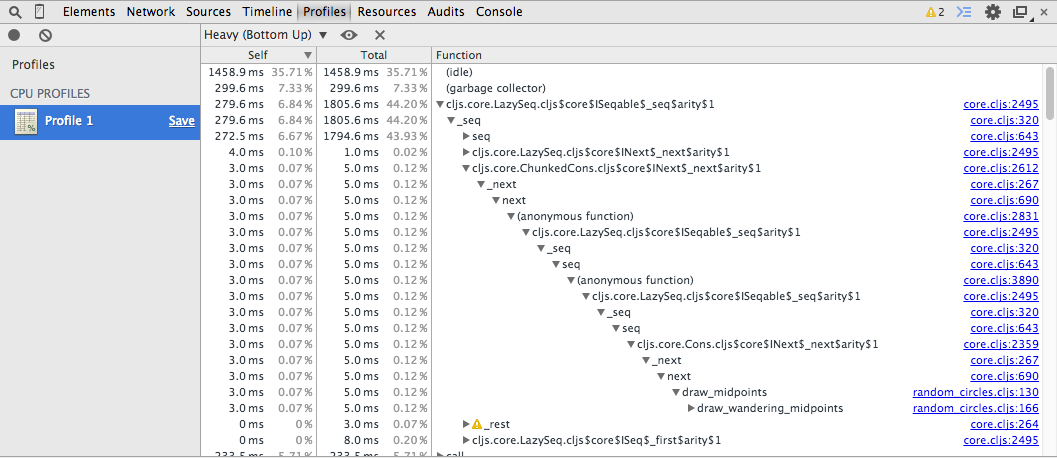
By comparison, the equivalent CoffeeScript trace is pretty straightforward.
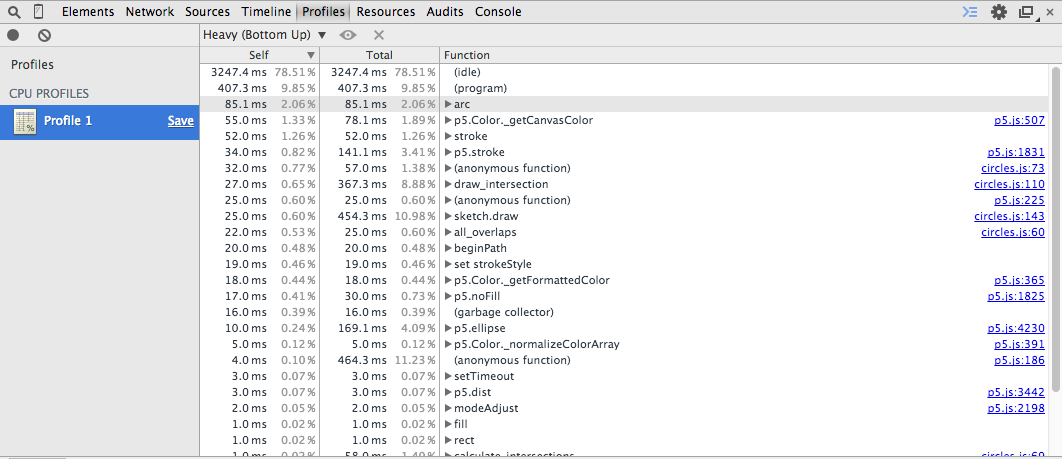
Even without digging in at all it’s clear that most of the time in the ClojureScript version is going to garbage collection and the collection functions themselves. This is an advantage that CoffeeScript also has on this scenario, since it gets to just use Javascript’s native arrays and we don’t need to continually dispose of calculated data for the circles (even though we do it for the intersections).
Some parting thoughts
Code length: the CoffeeScript implementation is 95 lines long, ClojureScript is 165. That I did not expect. The latter has a different indentation and could probably be compacted, but I’m not sure how readable the actual functions would end up without extracting some datatype values on let.
Mutability: I could write the ClojureScript version with mutable datatypes, but that would also make the code longer and less readable. I may try it for performance’s sake - I expect however that while it would remove the GC hit, the time spent on the CLJS function cost would still remain.
Reducing iterations: ClojureScript implementation can likely be improved by having the functions that iterate over circles be less independent so that we perform all actions at once. In this way, instead of doing first a pass that figures out the overlap and then another that draws it, we could do a single pass that takes care of both.
P5.js vs. Processing.js: One somewhat embarrassing note is that I realized too late that I had written the ClojureScript example against Processing.js and the CoffeeScript against P5.js… which turns out aren’t quite the same thing. As you’ve seen on the Profiling section, however, the actual rendering library was not the main performance bottleneck. I also found an article pointing out that Processing.js actually has a performance advantage when rendering, so I don’t expect rewriting the CoffeeScript version to use it would make any significant difference in favor of ClojureScript.
The source: Right, sources. CoffeeScript version, requiring P5.js; and the ClojureScript implementation, requiring Quil.